Intrinsic programming
Contents
Intrinsic programming#
1. SIMD#
Overview
Modern CPUs rely on parallelism to improve performance
Task parallelism: multicores and hyperthreadings
Instruction paralellism: mutliple instructions are executed concurrently by a single CPU.
Older CPUs (Pentium)
Instructions are executed via a pipeline fashion
Recent CPUs
Vector operations
Instructions operate on 4 to 8 inputs, yielding 4 or 8 results in a single clock cycle
Single Instruction, Multiple Data
SIMD concepts
CPU uses registers to store data to operate on
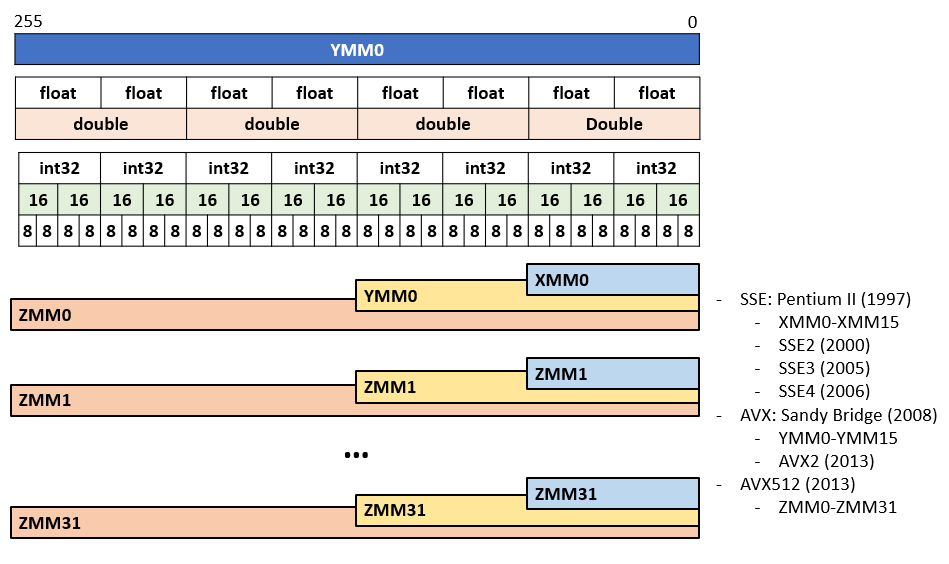
Basic registers:
32-bit and 64-bit
Each register holds a single scalar value
Vector registers:
Stores 4 (SSE) or 8 (AVX) scalar values.
An instruction can be applied on an entire vector register.
SSE and AVX
SSE: Streaming SIMD Extensions
Single instruction, multiple data (SIMD instruction set)
Advanced Vector Extensions SIMD
2. SIMD in practice#
Key concept
Adjacent values in memory that can be operated in parallel.
Loop unrolling
Recalling CSC 231: Data locality
for (int i = 0; i < 1000; i++)
x[i] = x[i] + s;
Given the cache size, successive instructions can be carried out without significant cache misses
for (int i = 0; i < 996; i=i-4) {
x[i] = x[i] + s;
x[i+1] = x[i+1] + s;
x[i+2] = x[i+2] + s;
x[i+3] = x[i+3] + s;
}
Intel SSE Instrinsics
The instructions in the unrolled loop can be packed into SSE/AVX registers so that they can be carried out in parallel.
3. Hands-on#
Unrolled loop
SSE example 1
__m128: Represents the contents of a SSE register used by the Intel Streaming SIMD.
__mm_loadu_ps: Loads four SP FP values in reverse order. The address
pneed not be 16-byte aligned.__mm_set1_ps: Sets four SP FP values to
w.__mm_mul_ps: Multiply fource single-precision FP values of
aandb.
SSE example 2
Challenge: Loop unrolling
Modify the below source code with the followings:
Add another function to carry out matrix multiplication with the two inner loops unrolled.
In the main function, create another matrix variable called unrolled_result[2][2]. Call the new function and the display function on this variable and confirm that you have the same results.
Challenge: SSE
Continue modifying the source code from the above challenge as followed:
Add yet another function to carry out matrix multiplication. This function should be based on the previous unrolled multiplication and utilize intrinsic programming to carry out multiple integer operations at the same time.
In the main function, create another matrix variable called sse_result[2][2]. Call the new function and the display function on this variable and confirm that you have the same results.
Challenge: Scaling up and SSE
Continue modifying the source code from the above challenge as followed:
Modify so that the program multiplies two 8x8 matrices.
Reimplement the unrolling/intrinsic multiplication:
Palmetto has different phases with different CPU generations, supporting from sse up to avx512.
Provide implementations for sse/avx/avx512, and confirm that it works on different Palmetto allocation request.
Call the new function and the display function on this variable and confirm that you have the same results.