MapReduce Programming Paradigm
Contents
MapReduce Programming Paradigm#
1. The reality of working with big data#
Hundreds or thousands of machines to support big data.
Distribute data for storage (not within the scope of this class).
Parallelize data computation (MapReduce)
Handle failure (MapReduce)
The paper: MapReduce: simplified data processing on large clusters
2. The reality of working with big data (as outlined by the paper)#
Challenges:
input data is usually large
the computations have to be distributed across hundreds or thousands of machines
finish in a reasonable amount of time.
Addressing these challenges causes the original simple computation to become obscured by large amounts of supporting complex codes.
What MapReduce does:
is a new abstraction
expresses the simple core computations
hides the messy details of parallelization, fault-tolerance, data distribution and load balancing in a library.
Why MapReduce?
inspired by the
_map_and_reduce_primitives present in Lisp and many other functional languages.Most data computations involve:
applying a
_map_operation to each logicalrecordin our input in order to compute a set of intermediate key/value pairs, and thenapplying a
_reduce_operation to all the values that shared the same key to combine the derived data appropriately.
3. MapReduce in a nutshell#
What is
map? A function/procedure that is applied to every individual elements of a collection/list/array/…
int square(x) { return x*x;}
map square [1,2,3,4] -> [1,4,9,16]
What is
reduce? A function/procedure that performs an operation on a list. This operation will fold/reduce this list into a single value (or a smaller subset)
reduce ([1,2,3,4]) using sum -> 10
reduce ([1,2,3,4]) using multiply -> 24
3. Word Count: the “Hello, World” of big data#
We have a large amount of text …
Could be stored in a single massive file.
Could be stored in multiple files.
We want to count the number of times each distinct word appears in the files
Sample applications:
Analyze web server logs to find popular URLs/keywords.
Analyze security logs to find incidents.
Standard parallel programming approach:
Count number of files or set up seek distances within a file.
Set number of processes
Possibly setting up dynamic workload assignment
A lot of data transfer
Significant coding effort
4. Word Count: MapReduce workflow#
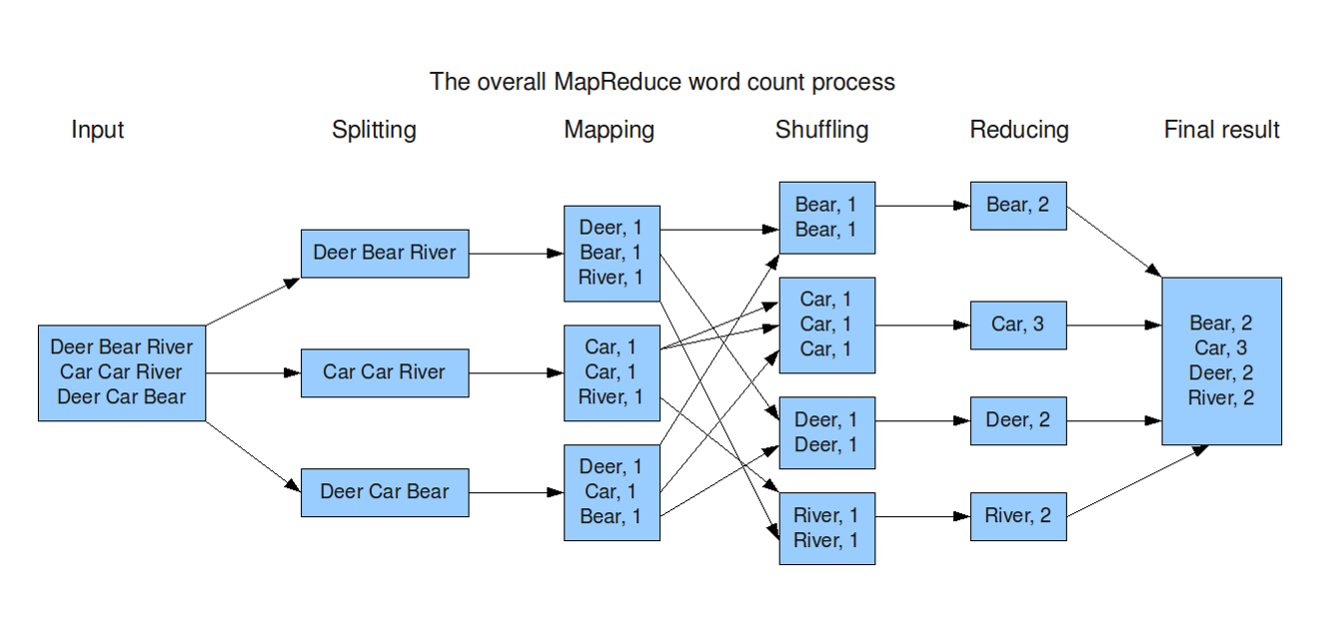
5. Word Count: MapReduce workflow - what do you really do#
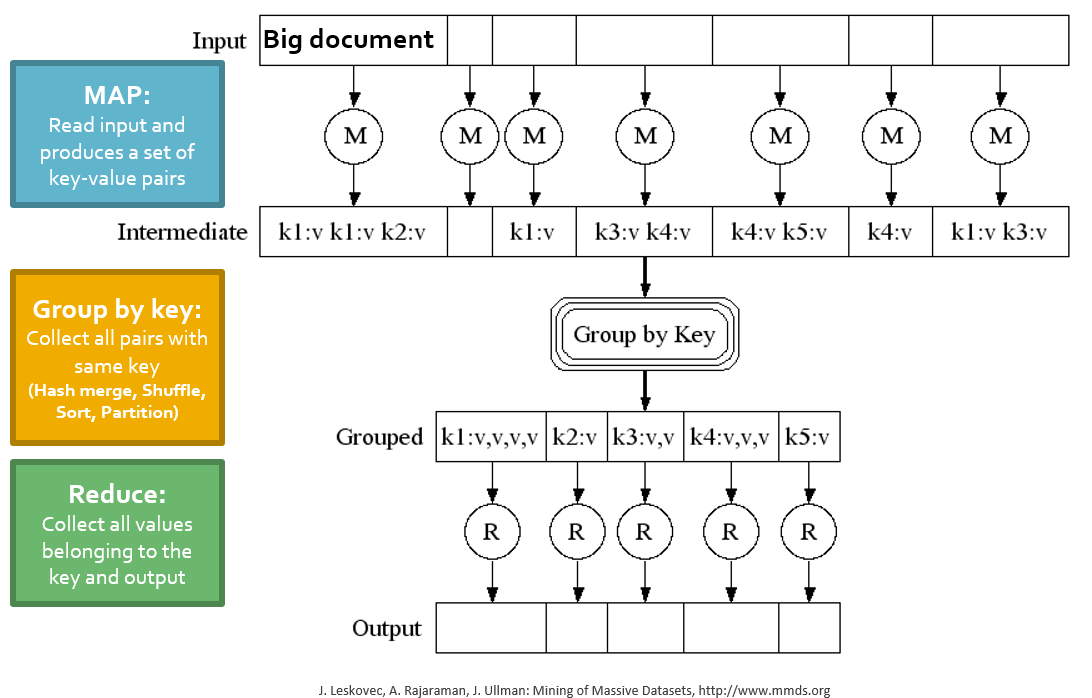
Input: a set of key-value pairs
Programmer specifies two methods:
Map(k, v) -> (k', v'):Takes a key-value pair and outputs a set of key-value pairs.
E.g., key is the filename, value is a single line in the file
There is one Map call for every (k,v) pair
Reduce(k2, <v'>) -> <k’, v’’>All values
v'with same keyk'are reduced together and processed inv'order.There is one Reduce function call per unique key
k'.
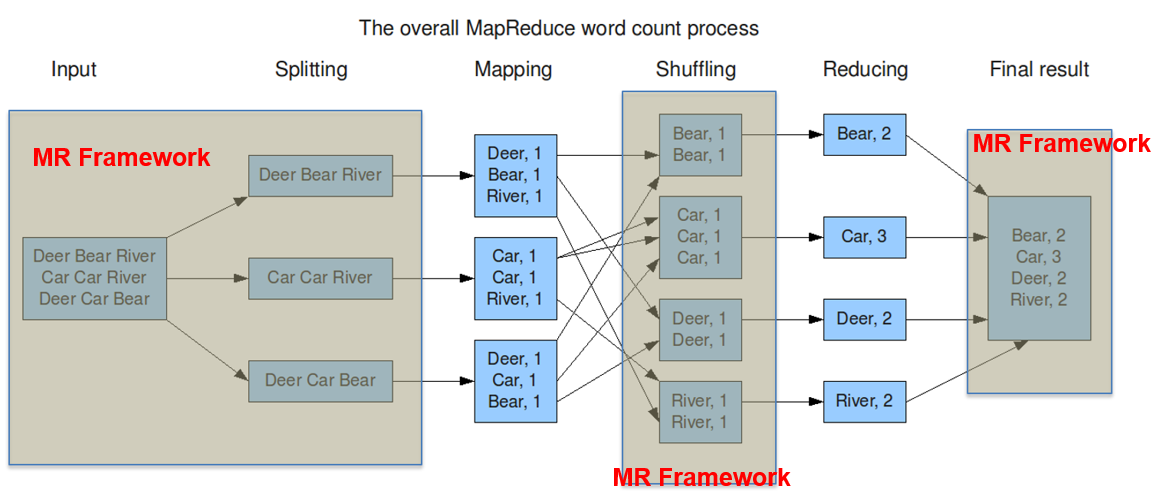
MapReduce environment takes care of:
Partitioning the input data
Scheduling the program’s execution across a set of machines
Performing the group by key step
Handling machine failures
Managing required inter-machine communication
6. Word Count: MapReduce workflow at scale#
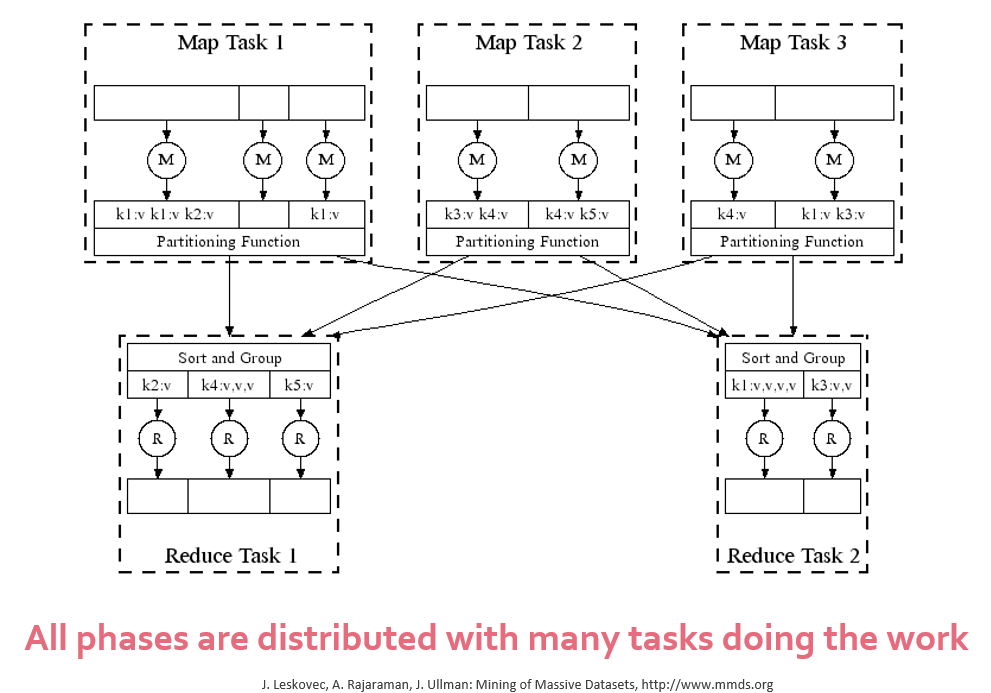
7. Applications that suit well with MapReduce programming paradigm#
Text tokenization, indexing, and search
Web access log stats
Inverted index construction
Term-vector per host
Distributed grep/sort
Graph creation
Web link-graph reversal (Google’s PageRank)
Data Mining and machine learning
Document clustering
Machine learning
Statistical machine translation