Spark computing environment
Contents
Spark computing environment#
1. What is Spark?#
A unified compute engine and a set of libraries for parallel data processing on computer clusters.
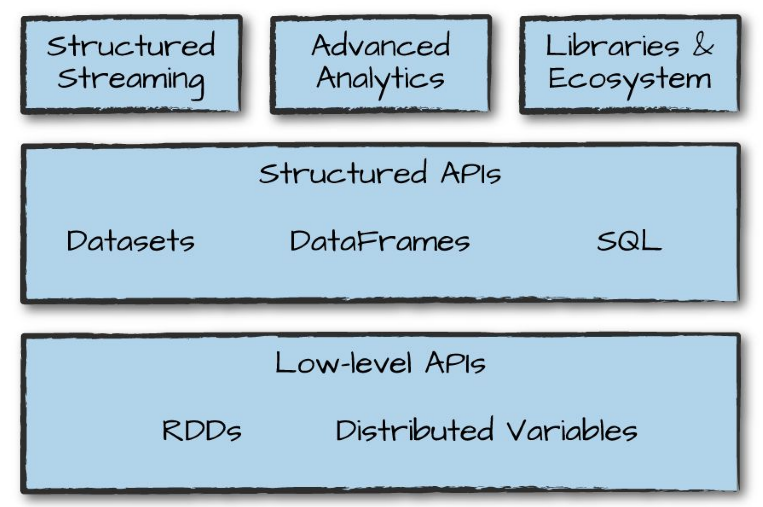
2. Design philosophy#
Unified: Spark supports a wide range of data analytic tasks over the same computing engine and a consistent set of APIs.Computing engine: Spark handles loading data from storage systems and perform computation on the data (in memory) rather than on permanent storage. To adhere to the data locality principle, Spark relies on APIs to provide a transparent common interface with different storage systems for all applications.Libraries: Via its APIs, Spark supports a wide array of internal and external libraries for complex data analytic tasks.
3. A brief history of Spark#
Research project at UC Berkeley AMP Lab in 2009 to address drawbacks of Hadoop MapReduce.
Paper published in 2010: Spark: Cluster Computing with Working Sets
Source code is contributed to Apache in 2013. The project had more than 100 contributors from more than 30 organizations outside UC Berkeley.
Version 1.0 was released in 2014.
Currently, Spark is being used extensively in academic and industry (NASA, CERN, Uber, Netflix …).
4. Spark applications#
Typically consists of a
driverprocess and a set ofexecutorprocesses.The
driverruns the main function and is responsible for:maintaining information about the Spark application,
responding to a user’s program or input, and
analyzing, distributing, and scheduling work across the executors.
The
executorscarry out the actual work assigned to them by thedriver.
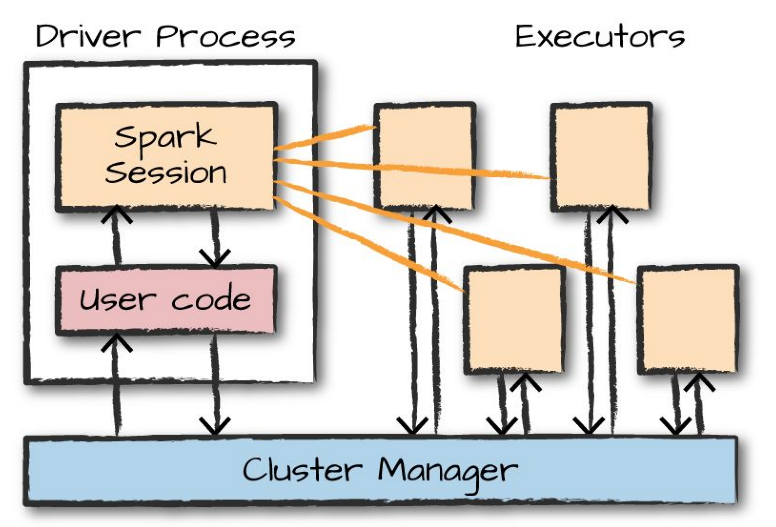
Spark also has a local mode (what we are using for this class), where driver and executors are simply processes on the same machine.
Spark application developed in local mode can be carried over almost
as-isto run in cluster mode (one of the attractiveness of Spark).Spark supports the following language APIs: Scala, Java, Python, SQL (ANSI SQL 2003 standard), and R.
5. Hands-on: Word Count in Spark#
Launch
Jupyter + Sparkon OpenOD.Launch a new Jupyter notebook
Enter the following Python code into the first cell of
spark-1, then run the cell.This code sets up the paths to Spark’s libraries and executables.
import sys
import os
import pyspark
print(os.environ['SPARK_ROOT'])
print(os.environ['SPARK_CONFIG_FILE'])
print(os.environ['SPARK_ROOT'])
print(os.environ['SPARK_MASTER_HOST'])
print(os.environ['SPARK_MASTER_PORT'])
Enter the following Python code into the next cell.
Pay attention to the strings inside
sc.textFile("A_STRING")andwordcount.saveAsTextFile("ANOTHER_STRING").These strings represent the path to where the original data is located (
sc.textFile) and where the output directory to be saved (wordcount.saveAsTextFile).Take your time here to organize the directories properly.
textFile = sc.textFile("/zfs/citi/complete-shakespeare.txt")
%%time
textFile.count()
wordcount = textFile.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
wordcount.saveAsTextFile("output-wordcount-01")
A successful run will generate the resulting output directory that contain
_SUCCESSflag file (size 0).
6. Data distribution in Spark#
Data in spark are managed as
distributed collection: when running on a cluster, parts of the data are distributed across different machines and are manipulated by different executors.To allow executor to perform work in parallel breaks up data into chunks called
partitions.Run the following code in a cell on
spark-1
textFile.getNumPartitions()
7. Transformation#
In Spark, the core data structures are
immutable, meaning they cannot be changed after creation.To
changea data collection means tocreatea new data collection that is atransformationfrom the old one.There are two types of transformation:
Narrow dependencies (1-to-1 transformation).
Wide dependencies (1-to-N transformation).
We can make a copy of our
textFilethat is distributed across more partitions. This is still anarrow dependenciestransformation.Run the following code in a cell
textFile_4 = textFile.repartition(4)
textFile_4.getNumPartitions()
Run the following code in a cell
wordcount = textFile_4.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
wordcount.saveAsTextFile("output-wordcount-02")
There are now four resulting output files:
8. Lazy evaluation and actions#
Transformationsare logical plan only.Spark will wait until the very last moment to execute the graph of computation instructions (the logical plan).
To trigger the computation, we run an
action.
wordcount = textFile_4.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
print(wordcount)
There are three kind of actions:
Actions to view data in the console (e.g.,
take).Action to collect data to native objects (e.g.,
collect).Action to write to output data sources (e.g.,
saveAsTextFile).
wordcount.take(10)
local_words = wordcount.collect()
print(local_words[1:10])
9. Hands on: Word Count workflow breakdown#
Run each of the following segments of Python code in a separate cell.
RDD of text file has a single item per row of collection.
textFile_4.take(10)
flatMapbreaks lines into lists of words, and concatenate these lists into a single new RDD.
wordcount_1 = textFile_4.flatMap(lambda line: line.split(" "))
wordcount_1.take(10)
Each item in this new RDD is turned into a (key/value) pair, with key is a word, and value is `.
wordcount_2 = wordcount_1.map(lambda word: (word, 1))
wordcount_2.take(10)
All pairs with the same key are
reducedtogether using pairwise summation to get the final count of each key.
wordcount_3 = wordcount_2.reduceByKey(lambda a, b: a + b)
wordcount_3.take(10)
Challenge 1#
Augment the mapping process of WordCount with a function to filter out punctuations and capitalization from the unique words
Hint: The string module is helpful for removing punctuation.
Solution
import string
translator = str.maketrans('', '', string.punctuation)
wordcount_enhanced = textFile.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word.translate(translator).lower(), 1)) \
.reduceByKey(lambda a, b: a + b)
wordcount_enhanced.take(100)
Challenge 2#
Look up the Spark Python API for filter.
Augment the results from Challenge 1 to remove the empty spaces (
'').
import string
translator = str.maketrans('', '', string.punctuation)
wordcount_enhanced = textFile.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word.translate(translator).lower(), 1)) \
.reduceByKey(lambda a, b: a + b)
wordcount_enhanced.take(100)
Solution
wordcount_filtered = wordcount_enhanced.filter(lambda x: x[0] != '')
wordcount_filtered.take(100)
Challenge 3#
Examing NLTK library: https://www.nltk.org/howto/stem.html
Use the NLTK library to augment the results from Challenge 2 to:
convert all words to their original root form
remove all stop-words