Introduction to MPI
Contents
Introduction to MPI#
1. History of MPI#
Message passing
Processes communicate via messages
Messages can be:
Raw data used in actual calculations
Signals and acknowledgements for the receiving processes regarding the workflow.
Early 80s
Various message passing environments were developed.
Many similar fundamental concepts:
Cosmic Cube and nCUBE/2 (Caltech),
P4 (Argonne),
PICL and PVM (Oakridge),
LAM (Ohio SC)
1991-1992
More than 80 researchers from different institutions in US and Europe agreed to develop and implement a common standard for message passing.
Follow-up first meeting of the working group hosted at Supercomputing 1992 in Minnesota.
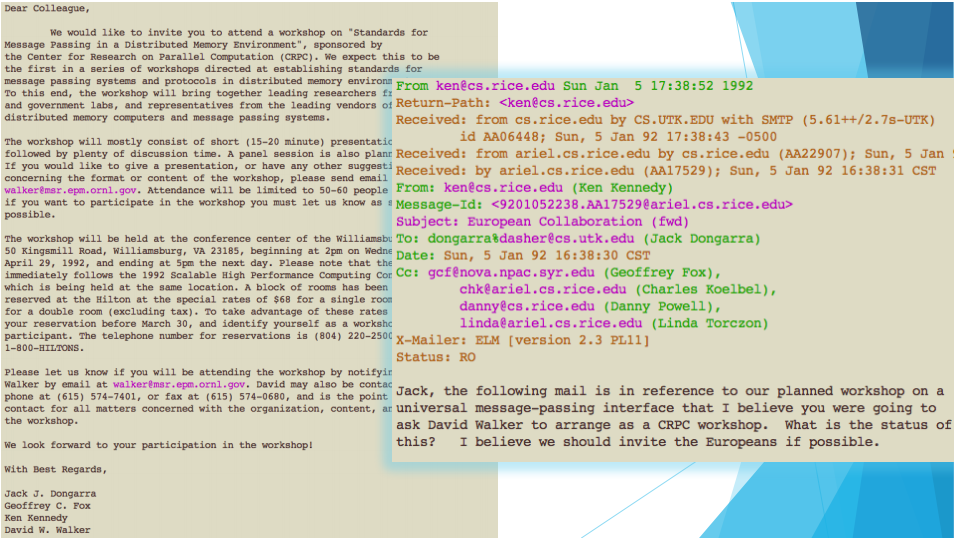
After finalization of working technical draft
MPI becomes the de-facto standard for distributed memory parallel programming.
Available on every popular operating system and architecture.
Interconnect manufacturers commonly provide MPI implementations optimized for their hardware.
MPI standard defines interfaces for C, C++, and Fortran.
Language bindings available for many popular languages (quality varies)
Python (mpi4py)
Java (no longer active)
1994: MPI-1
Communicators
Information about the runtime environments
Creation of customized topologies
Point-to-point communication
Send and receive messages
Blocking and non-blocking variations
Collectives
Broadcast and reduce
Gather and scatter
1998: MPI-2
One-sided communication (non-blocking)
Get & Put (remote memory access)
Dynamic process management
Spawn
Parallel I/O
Multiple readers and writers for a single file
Requires file-system level support (LustreFS, PVFS)
2012: MPI-3
Revised remote-memory access semantic
Fault tolerance model
Non-blocking collective communication
Access to internal variables, states, and counters for performance evaluation purposes
2021: MPI-4
Big Count operations (beyond int)
Persistent Collectives
Partitioned Communication
Topology Solutions
Simple fault handling to enable fault tolerance solutions
…
2. Hands-on: create and compile MPI codes#
In your VSCode launch app, add
openmpi/4.1.3-gcc/9.5.0-ucxto the `List of modules to be loaded, separate by an empty space’ box.Once the Code Server app is launched:
Create a directory named
intro-mpiChange into
intro-mpi
Inside
intro-mpi, create a file namedfirst.cwith the following contents
Compile and run
first.c:
$ mpicc -o first first.c
$ mpirun -np 1 ./first
$ mpirun -np 2 ./first
$ mpirun -np 4 ./first
3. MPI in a nutshell#
Overview
All processes are launched at the beginning of the program execution.
The number of processes are user-specified
This number could be modified during runtime (MPI-2 standards)
Typically, this number is matched to the total number of cores available across the entire cluster
All processes have their own memory space and have access to the same source codes.
MPI_Init: indicates that all processes are now working in message-passing mode.MPI_Finalize: indicates that all processes are now working in sequential mode (only one process active) and there are no more message-passing activities.
Core functions
MPI_COMM_WORLD: Global communicatorMPI_Comm_rank: return the rank of the calling processMPI_Comm_size: return the total number of processes that are part of the specified communicator.MPI_Get_processor_name: return the name of the processor (core) running the process.
MPI communicators (first defined in MPI-1)
MPI defines communicator groups for point-to-point and collective communications:
Unique IDs (rank) are defined for individual processes within a communicator group.
Communications are performed based on these IDs.
Default global communication (
MPI_COMM_WORLD) contains all processes.For
Nprocesses, ranks go from0toN−1.
Hands-on: hello.c
Inside
intro-mpi, create a file namedhello.cwith the following contents
Compile and run
hello.c:
$ mpicc -o hello hello.c
$ mpirun -np 1 ./hello
$ mpirun -np 2 ./hello
$ mpirun -np 4 ./hello
Hands-on: evenodd.c
In MPI, processes’ ranks are used to enforce execution/exclusion of code segments within the original source code.
Inside
intro-mpi, create a file namedevenodd.cwith the following contents
Compile and run
evenodd.c:
$ mpicc -o evenodd evenodd.c
$ mpirun -np 1 ./evenodd
$ mpirun -np 2 ./evenodd
$ mpirun -np 4 ./evenodd
Hands-on: rank_size.c
In MPI, the values of ranks and size can be used as means to calculate and distribute workload (data) among the processes.
Inside
intro-mpi, create a file namedrank_size.cwith the following contents
Compile and run
rank_size.c:
$ mpicc -o rank_size rank_size.c
$ mpirun -np 1 ./rank_size
$ mpirun -np 2 ./rank_size
$ mpirun -np 4 ./rank_size